

Bity, bajty i adresowanie pamięci
W lekcji 1.3 -- Wprowadzenie do obiektów i zmiennych, rozmawialiśmy o tym, że zmienne to nazwy fragmentu pamięci, w którym można przechowywać informacje. Krótko mówiąc, komputery mają pamięć o dostępie swobodnym (RAM), z której mogą korzystać programy. Kiedy zdefiniowana jest zmienna, część tej pamięci jest zarezerwowana dla tej zmiennej.
Najmniejszą jednostką pamięci jest cyfra binarna (zwana także bit), która może przechowywać wartość 0 lub 1. Bit można traktować jak tradycyjny włącznik światła — albo światło jest wyłączone (0), albo włączone (1). Nie ma czegoś pomiędzy. Jeśli spojrzysz na losowy segment pamięci, zobaczysz tylko…011010100101010… lub jakąś ich kombinację.
Pamięć jest zorganizowana w kolejne jednostki zwane adresami pamięci (lub adresami w skrócie). Podobnie jak adres ulicy może zostać wykorzystany do znalezienia danego domu na ulicy, adres pamięci pozwala nam znaleźć zawartość pamięci w określonym miejscu i uzyskać do niej dostęp.
Być może, co zaskakujące, we współczesnych architekturach komputerów każdy bit nie ma własnego, unikalnego adresu pamięci. Dzieje się tak dlatego, że liczba adresów pamięci jest ograniczona, a potrzeba dostępu do danych bit po bicie jest rzadka. Zamiast tego każdy adres pamięci przechowuje 1 bajt danych. bajt to grupa bitów, na których operuje się jako na jednostce. Współczesny standard zakłada, że bajt składa się z 8 kolejnych bitów.
Kluczowa informacja
W C++ zazwyczaj pracujemy z fragmentami danych o rozmiarze „bajtowym”.
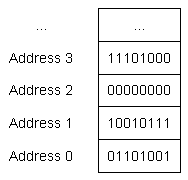
Poniższy rysunek przedstawia niektóre sekwencyjne adresy pamięci wraz z odpowiadającymi im bajtami danych:
Na marginesie…
Niektóre starsze lub niestandardowe maszyny mogą mieć bajty o innym rozmiarze (od 1 do 48 bitów) - jednak my generalnie nie trzeba się tym martwić, ponieważ współczesny standard de facto stanowi, że bajt ma 8 bitów. Na potrzeby tych tutoriali założymy, że bajt ma 8 bitów.
Typy danych
Ponieważ wszystkie dane na komputerze to tylko sekwencja bitów, używamy w skrócie typ danych (często nazywany typ ), aby powiedzieć kompilatorowi, jak w jakiś znaczący sposób interpretować zawartość pamięci. Widziałeś już jeden przykład typu danych: liczbę całkowitą. Kiedy deklarujemy zmienną jako liczbę całkowitą, mówimy kompilatorowi, że „fragment pamięci używany przez tę zmienną będzie interpretowany jako wartość całkowita”.
Kiedy nadasz obiektowi wartość, kompilator i procesor zajmują się zakodowaniem Twojej wartości w odpowiedniej sekwencji bitów dla tego typu danych, które są następnie przechowywane w pamięci (pamiętaj: pamięć może przechowywać tylko bity). Na przykład, jeśli obiektowi całkowitemu przypiszesz wartość 65, wartość ta zostanie przekonwertowana na sekwencję bitów 0100 0001 i zapisana w pamięci przypisanej do obiektu.
I odwrotnie, gdy obiekt zostanie oceniony pod kątem wygenerowania wartości, ta sekwencja bitów zostanie odtworzona z powrotem do pierwotnej wartości. Oznacza to, że 0100 0001 jest konwertowany z powrotem na wartość 65.
Na szczęście kompilator i procesor wykonują tutaj całą ciężką pracę, więc generalnie nie musisz się martwić, w jaki sposób wartości są konwertowane na sekwencje bitów i z powrotem.
Wszystko, co musisz zrobić, to wybrać typ danych dla swojego obiektu, który najlepiej pasuje do zamierzonego zastosowania.
Dane podstawowe typy
Język C++ zawiera wiele predefiniowanych typów danych dostępnych do użytku. Najbardziej podstawowe z tych typów nazywane są podstawowymi typami danych (nieformalnie czasami nazywanymi typami podstawowymi lub typami pierwotnymi).
Oto lista podstawowych typów danych, z których część już widziałeś:
| Typy | Kategoria | Znaczenie | Przykład |
|---|---|---|---|
| float double long double | Pływające Punkt | liczba z częścią ułamkową | 3.14159 |
| bool | Cała (Boolean) | prawda lub fałsz | prawda |
| char wchar_t char8_t (C++20) char16_t (C++11) char32_t (C++11) | Integral (znak) | pojedynczy znak tekstu | ‘c’ |
| short int int long int long long int (C++11) | Integral (Całkowita) | dodatnie i ujemne liczby całkowite, w tym 0 | 64 |
| std::nullptr_t (C++11) | Wskaźnik zerowy | wskaźnik zerowy | nullptr |
| void | Void | brak typu | n/a |
Ten rozdział poświęcony jest badaniu tych podstawowych typów danych w szczegóły (z wyjątkiem std::nullptr_t, który omówimy, gdy będziemy mówić o wskaźnikach).
Liczba całkowita a typy całkowite
W matematyce „liczba całkowita” to liczba bez części dziesiętnej ani ułamkowej, włączając liczby ujemne i dodatnie oraz zero. Termin „całka” ma kilka różnych znaczeń, ale w kontekście C++ jest używany w znaczeniu „jak liczba całkowita”.
Standard C++ definiuje następujące terminy:
- Klasa standardowe typy całkowite są
short,int,long,long long(w tym ich warianty ze znakiem i bez znaku). - Klasa typy całkowe są
bool, różne typy znaków i standardowa liczba całkowita typy.
Wszystkie typy całkowite są przechowywane w pamięci jako wartości całkowite, ale tylko standardowe typy całkowite będą wyświetlane jako wartości całkowite na wyjściu. Omówimy, co bool i typy znaków robią podczas wyprowadzania w odpowiednich lekcjach.
Standard C++ również wyraźnie zauważa, że „typy całkowite” są synonimem „typów całkowitych”. Jednak tradycyjnie „typy całkowite” są częściej używane jako skrót dla „standardowych typów całkowitych”.
Należy również pamiętać, że termin „typy całkowite” obejmuje tylko typy podstawowe. Oznacza to, że typy niefundamentalne (takie jak enum i enum class) nie są typami całkowitymi, nawet jeśli są przechowywane jako liczby całkowite (a w przypadku enum również wyświetlane jako jeden).
Inne zestawy typów
C++ zawiera trzy zestawy typów.
Pierwsze dwa są wbudowane w sam język (i nie wymagają dołączenia nagłówka do użycia):
- „Podstawowe typy danych” zapewniają najbardziej podstawowe i niezbędne typy danych.
- „Złożone typy danych” zapewniają bardziej złożone typy danych i pozwalają na tworzenie niestandardowych (zdefiniowanych przez użytkownika) typów danych. Omówimy je w lekcji 12.1 — Wprowadzenie do złożonych typów danych.
Rozróżnienie między typami podstawowymi i złożonymi nie jest aż tak interesujące ani istotne, dlatego ogólnie dobrze jest traktować je jako pojedynczy zestaw typów.
Trzeci (i największy) zestaw typów jest udostępniany przez standardową bibliotekę C++. Ponieważ biblioteka standardowa jest zawarta we wszystkich dystrybucjach C++, typy te są szeroko dostępne i zostały ustandaryzowane pod kątem zgodności. Użycie typów z biblioteki standardowej wymaga włączenia odpowiedniego nagłówka i linkowania w bibliotece standardowej.
Nomenklatura
Termin „typ wbudowany” jest najczęściej używany jako synonim podstawowych typów danych. Jednakże Stroustrup i inni używają tego terminu do określenia zarówno podstawowych, jak i złożonych typów danych (oba są wbudowane w język podstawowy). Ponieważ termin ten nie jest dobrze zdefiniowany, zalecamy jego unikanie.
Godnym pominięciem w powyższej tabeli typów podstawowych jest typ danych do obsługi ciągów (sekwencja znaków zwykle używana do reprezentowania tekstu). Dzieje się tak, ponieważ we współczesnym C++ ciągi znaków są częścią standardowej biblioteki. Chociaż w tym rozdziale skupimy się na typach podstawowych, ponieważ podstawowe użycie ciągów jest proste i przydatne, w następnym rozdziale przedstawimy ciągi znaków (na lekcji 5.7 — Wprowadzenie do std::string).
Przyrostek _t
Wiele typów zdefiniowanych w nowszych wersjach C++ (np. std::nullptr_t) używa przyrostka _t. Ten przyrostek oznacza „typ” i jest powszechny nomenklatura stosowana do współczesnych typów.
Jeśli widzisz coś z przyrostkiem _t, prawdopodobnie jest to typ. Jednak wiele typów nie ma przyrostka _t, więc nie jest on konsekwentnie stosowany.