

W lekcji 2.8 -- Programy z wieloma plikami kodu, omawialiśmy, w jaki sposób programy mogą być dzielone na wiele plików. Omówiliśmy także, w jaki sposób używane są deklaracje forward, aby umożliwić kodowi z jednego pliku dostęp do czegoś zdefiniowanego w innym pliku.
Gdy programy zawierają tylko kilka małych plików, ręczne dodanie kilku deklaracji forward na górze każdego pliku nie jest takie złe. Jednakże w miarę jak programy stają się większe (i wykorzystują więcej plików i funkcji), konieczność ręcznego dodawania dużej liczby (prawdopodobnie różnych) deklaracji forward na górze każdego pliku staje się niezwykle uciążliwa. Na przykład, jeśli masz program składający się z 5 plików, z których każdy wymaga 10 deklaracji forward, będziesz musiał skopiować/wkleić 50 deklaracji forward. Rozważmy teraz przypadek, w którym masz 100 plików i każdy z nich wymaga 100 deklaracji forward. To po prostu nie da się skalować!
Aby rozwiązać ten problem, programy C++ zazwyczaj przyjmują inne podejście.
Pliki nagłówkowe
Pliki kodu C++ (z rozszerzeniem .cpp) nie są jedynymi plikami powszechnie spotykanymi w programach C++. Drugi typ pliku nazywany jest plikiem nagłówkowym. Pliki nagłówkowe mają zwykle rozszerzenie .h, ale czasami można je zobaczyć z rozszerzeniem .hpp lub bez rozszerzenia.
Konwencjonalnie pliki nagłówkowe służą do propagowania kilku powiązanych deklaracji forward do pliku z kodem.
Kluczowa informacja
Pliki nagłówkowe pozwalają nam umieścić deklaracje w jednym miejscu, a następnie zaimportować je tam, gdzie ich potrzebujemy. Może to zaoszczędzić dużo pisania w programach wieloplikowych.
Korzystanie ze standardowych plików nagłówkowych biblioteki
Rozważ następujący program:
#include <iostream>
int main()
{
std::cout << "Hello, world!";
return 0;
}Ten program wypisuje komunikat „Witaj, świecie!” do konsoli za pomocą std::cout. Jednak ten program nigdy nie dostarczył definicji ani deklaracji std::cout, więc skąd kompilator wie, czym std::cout jest?
Odpowiedź jest taka, że std::cout został zadeklarowany w przód w pliku nagłówkowym „iostream”. Kiedy #include <iostream> żądamy, aby preprocesor skopiował całą zawartość (w tym deklaracje forward dla std::cout) z pliku o nazwie „iostream” do pliku wykonującego #include.
Kluczowa informacja
Gdy #include plikujesz, zawartość dołączonego pliku jest wstawiana w miejscu dołączenia. Zapewnia to użyteczny sposób pobierania deklaracji z innego pliku.
Zastanów się, co by się stało, gdyby nagłówek iostream nie istniał. Gdziekolwiek użyłeś std::cout, musiałbyś ręcznie wpisać lub skopiować wszystkie deklaracje związane z std::cout na górę każdego pliku, który użył std::cout! Wymagałoby to dużej wiedzy na temat sposobu std::cout deklarowania i wymagałoby mnóstwo pracy. Co gorsza, jeśli dodano lub zmieniono prototyp funkcji, musielibyśmy ręcznie zaktualizować wszystkie deklaracje forward.
Znacznie łatwiej jest po prostu #include <iostream>!
Używać plików nagłówkowych do propagowania deklaracji forward
Powróćmy teraz do przykładu, który omawialiśmy w poprzedniej lekcji. Kiedy skończyliśmy, mieliśmy dwa pliki add.cpp i main.cpp, które wyglądały tak:
add.cpp:
int add(int x, int y)
{
return x + y;
}main.cpp:
#include <iostream>
int add(int x, int y); // deklaracja do przodu przy użyciu prototypu funkcji
int main()
{
std::cout << "The sum of 3 and 4 is " << add(3, 4) << '\n';
return 0;
}(Jeśli odtwarzasz ten przykład od zera, nie zapomnij dodać add.cpp do swojego projektu, aby został skompilowany.)).
W tym przykładzie użyliśmy deklaracji forward, aby kompilator wiedział, jaki identyfikator add jest podczas kompilacji main.cpp. Jak wspomniano wcześniej, ręczne dodawanie deklaracji forward dla każdej funkcji, której chcesz użyć, a która znajduje się w innym pliku, może szybko stać się nudne.
Napiszmy plik nagłówkowy, aby uwolnić się od tego ciężaru. Napisanie pliku nagłówkowego jest zaskakująco łatwe, ponieważ pliki nagłówkowe składają się tylko z dwóch części:
- osłona nagłówka, którą omówimy bardziej szczegółowo w następnej lekcji (2.12 -- Strażnicy nagłówka).
- Rzeczywista zawartość pliku nagłówkowego, która powinna być deklaracjami forward dla wszystkich identyfikatorów, które chcemy, aby inne pliki mogły widzieć.
Dodanie pliku nagłówkowego do projektu działa analogicznie do dodawania pliku źródłowego (opisanego w lekcji 2.8 -- Programy z wieloma plikami kodu).
Jeśli używasz IDE, wykonaj te same kroki i po wyświetleniu pytania wybierz „Nagłówek” zamiast „Źródło”. Plik nagłówkowy powinien pojawić się jako część Twojego projekt.
Jeśli używasz wiersza poleceń, po prostu utwórz nowy plik w swoim ulubionym edytorze w tym samym katalogu, w którym znajdują się pliki źródłowe (.cpp). W przeciwieństwie do plików źródłowych, pliki nagłówkowe powinny nie zostać dodane do polecenia kompilacji (są domyślnie zawarte w instrukcjach #include i kompilowane jako część plików źródłowych).
Najlepsza praktyka
Preferuj przyrostek .h podczas nadawania nazw plikom nagłówkowym (chyba że Twój projekt jest już zgodny z innym konwencja).
Jest to wieloletnia konwencja dla plików nagłówkowych C++ i większość IDE nadal domyślnie używa .h zamiast innych opcji.
Pliki nagłówkowe są często łączone w pary z plikami kodu, przy czym plik nagłówkowy zawiera deklaracje forward dla odpowiedniego pliku z kodem. Ponieważ nasz plik nagłówkowy będzie zawierał deklarację forward dla funkcji zdefiniowanych w add.cpp, nazwiemy nasz nowy nagłówek. plik add.h.
Najlepsza praktyka
Jeśli plik nagłówkowy jest sparowany z plikiem kodu (np. add.h z add.cpp), oba powinny mieć tę samą nazwę bazową (add).
Oto nasz gotowy plik nagłówkowy:
add.h:
// Naprawdę powinniśmy mieć tutaj osłonę nagłówka, ale pominiemy ją dla uproszczenia (zabezpieczenia nagłówka omówimy w następnej lekcji)
// To jest zawartość pliku .h, w którym znajdują się deklaracje
int add(int x, int y); // prototyp funkcji dla add.h -- nie zapomnij o średniku!Aby użyć tego pliku nagłówkowego w main.cpp, musimy aby #włączyć go (używając cudzysłowów, a nie nawiasów ostrokątnych).
main.cpp:
#include "add.h" // Wstaw zawartość add.h w tym miejscu. Zwróć uwagę na użycie tutaj podwójnych cudzysłowów.
#include <iostream>
int main()
{
std::cout << "The sum of 3 and 4 is " << add(3, 4) << '\n';
return 0;
}add.cpp:
#include "add.h" // Wstaw zawartość add.h w tym miejscu. Zwróć uwagę na użycie tutaj podwójnych cudzysłowów.
int add(int x, int y)
{
return x + y;
}Kiedy preprocesor przetwarza linię #include "add.h" , kopiuje w tym miejscu zawartość add.h do bieżącego pliku. Ponieważ nasz add.h zawiera deklarację forward dla funkcji add(), to forward. deklaracja zostanie skopiowana do main.cpp. Efektem końcowym jest program, który jest funkcjonalnie taki sam, jak ten, w którym ręcznie dodaliśmy deklarację forward na górze main.cpp.
W rezultacie nasz program będzie się poprawnie kompilował i linkował.
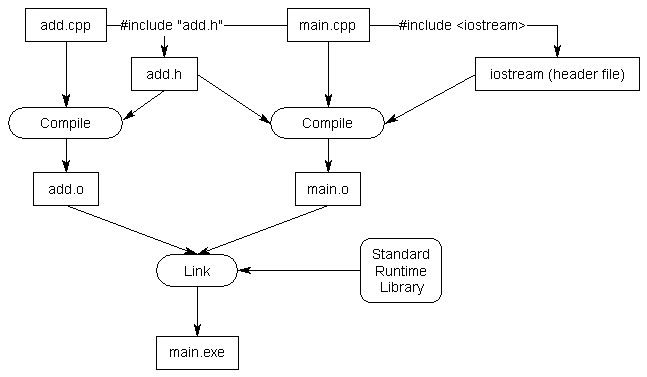
Uwaga: Na powyższej grafice „Standardowa biblioteka uruchomieniowa” powinna być oznaczona jako „Standardowa biblioteka C++”.
Jak umieszczać definicje w nagłówku plik powoduje naruszenie reguły jednej definicji
Na razie powinieneś unikać umieszczania definicji funkcji lub zmiennych w plikach nagłówkowych. Takie postępowanie zazwyczaj spowoduje naruszenie reguły jednej definicji (ODR) w przypadkach, gdy plik nagłówkowy jest zawarty w więcej niż jednym pliku źródłowym.
Powiązana treść
Regułę jednej definicji (ODR) omówiliśmy w lekcji 2.7 -- Deklaracje przesyłania dalej i definicje.
Zilustrujmy, jak to się dzieje:
add.h:
// Naprawdę powinniśmy mieć tutaj osłonę nagłówka, ale pominiemy ją dla uproszczenia (zabezpieczenia nagłówka omówimy w następnej lekcji)
// definicja dla add() w pliku nagłówkowym -- nie rób tego!
int add(int x, int y)
{
return x + y;
}main.cpp:
#include "add.h" // Zawartość add.h skopiowana tutaj
#include <iostream>
int main()
{
std::cout << "The sum of 3 and 4 is " << add(3, 4) << '\n';
return 0;
}add.cpp:
#include "add.h" // Zawartość add.h skopiowana tutajPo wywołaniu main.cpp jest kompilowany, #include "add.h" zostanie zastąpione zawartością add.h , a następnie skompilowany. Dlatego kompilator skompiluje coś, co wygląda podobnie to:
main.cpp (po wstępnym przetworzeniu):
// z add.h:
int add(int x, int y)
{
return x + y;
}
// zawartość nagłówka iostream tutaj
int main()
{
std::cout << "The sum of 3 and 4 is " << add(3, 4) << '\n';
return 0;
}To się skompiluje prawidłowo.
Kiedy kompilator się skompiluje, add.cpp, instrukcja #include "add.h" zostanie zastąpione zawartością add.h , a następnie skompilowane. Dlatego kompilator skompiluje coś takiego:
add.cpp (po przetwarzanie wstępne):
int add(int x, int y)
{
return x + y;
}To również się skompiluje.
Na koniec linker zostanie uruchomiony. Linker zobaczy, że istnieją teraz dwie definicje funkcji add(): jedna w main.cpp i jedna w add.cpp. Jest to naruszenie części 2 ODR, która stwierdza: „W danym programie zmienna lub funkcja normalna może mieć tylko jedną. definicja.”
Najlepsza praktyka
Nie umieszczaj definicji funkcji i zmiennych w plikach nagłówkowych (na razie).
Zdefiniowanie któregokolwiek z nich w pliku nagłówkowym prawdopodobnie spowoduje naruszenie reguły jednej definicji (ODR), jeśli ten nagłówek zostanie następnie #uwzględniony w więcej niż jednym pliku źródłowym (.cpp).
Nota autora
W przyszłych lekcjach napotkamy dodatkowe rodzaje definicji, które można bezpiecznie zdefiniować w plikach nagłówkowych (ponieważ są one wyłączone z ODR). Obejmuje to definicje funkcji wbudowanych, zmiennych wbudowanych, typów i szablonów. Omówimy to szerzej, gdy przedstawimy każdy z nich.
Pliki źródłowe powinny zawierać sparowany nagłówek
W C++ najlepszą praktyką jest, aby pliki kodu #uwzględniały sparowany plik nagłówkowy (jeśli taki istnieje). Pozwala to kompilatorowi wyłapać określone rodzaje błędów w czasie kompilacji, a nie w czasie łączenia. Na przykład:
add.h:
// Naprawdę powinniśmy mieć tutaj osłonę nagłówka, ale pominiemy ją dla uproszczenia (zabezpieczenia nagłówka omówimy w następnej lekcji)
int add(int x, int y);main.cpp:
#include "add.h"
#include <iostream>
int main()
{
std::cout << "The sum of 3 and 4 is " << add(3, 4) << '\n';
return 0;
}add.cpp:
#include "add.h" // kopiuje dalej deklarację z add.h tutaj
double add(int x, int y) // ups, typ zwracany to double zamiast int
{
return x + y;
}Po wywołaniu add.cpp jest skompilowany, deklaracja forward int add(int x, int y) zostanie skopiowana do add.cpp w miejscu #include. Kiedy kompilator osiągnie definicję double add(int x, int y), zauważy, że typy zwracane deklaracji forward i definicja nie są zgodne. Ponieważ funkcje nie mogą różnić się jedynie typem zwracanym, kompilator natychmiast zgłosi błąd i przerwie kompilację. W większym projekcie może to zaoszczędzić dużo czasu i pomóc zlokalizować, gdzie leży problem.
Na marginesie…
Niestety to nie zadziała, jeśli jest to parametr innego typu niż zwracany. Dzieje się tak, ponieważ C++ obsługuje przeciążone funkcje (funkcje o tej samej nazwie, ale różnych typach parametrów), więc kompilator przyjmie, że funkcja z niedopasowanym typem parametru jest innym przeciążeniem. Nie można wygrać ich wszystkich.
Jeśli #include "add.h" nie ma, kompilator nie wykryje problemu, ponieważ nie widzi niezgodności. Musimy poczekać do czasu połączenia, aż problem wyjdzie na jaw.
W przyszłych lekcjach zobaczymy także wiele przykładów, w których zawartość wymagana przez plik źródłowy jest zdefiniowana w sparowanym nagłówku. W takich przypadkach dołączenie nagłówka jest koniecznością.
Najlepsza praktyka
Pliki źródłowe powinny #dołączać sparowany plik nagłówkowy (jeśli taki istnieje).
Chociaż preprocesor chętnie to zrobi, generalnie nie powinieneś #include plików .cpp. Należy je dodać do projektu i skompilować.
Jest ku temu wiele powodów:
- Może to spowodować kolizje nazewnictwa między plikami źródłowymi.
- W dużym projekcie może być trudno uniknąć problemów z regułami jednej definicji (ODR).
- Każda zmiana w takim pliku .cpp spowoduje, że zarówno plik .cpp, jak i każdy inny plik .cpp zawierający go do ponownej kompilacji, co może zająć dużo czasu. Nagłówki zmieniają się rzadziej niż pliki źródłowe.
- Jest to niekonwencjonalne.
Najlepsza praktyka
Unikaj #dołączania plików .cpp.
Wskazówka
Jeśli Twój projekt nie zostanie skompilowany, jeśli #nie dołączysz plików .cpp, oznacza to, że te pliki .cpp nie są kompilowane w ramach Twojego projektu. Dodaj je do swojego projektu lub wiersza poleceń, aby zostały skompilowane.
Rozwiązywanie problemów
Jeśli pojawi się błąd kompilatora wskazujący, że nie znaleziono pliku add.h , upewnij się, że plik ma naprawdę nazwę add.h. W zależności od tego, jak go utworzyłeś i nazwałeś, możliwe, że plik mógł mieć jakąś nazwę add (bez rozszerzenia) lub add.h.txt lub add.cpp. Upewnij się także, że znajduje się on w tym samym katalogu, co reszta plików z kodem.
Jeśli pojawi się błąd linkera dotyczący niezdefiniowania funkcji add , upewnij się, że w swoim projekcie umieściłeś plik add.cpp , aby definicję funkcji add można było połączyć z programem.
Prawdopodobnie ciekawi Cię, dlaczego używamy nawiasów kątowych dla iostream i podwójnych cudzysłowów dla add.h. Możliwe, że plik nagłówkowy o tej samej nazwie może znajdować się w wielu katalogach. Użycie przez nas nawiasów kątowych zamiast podwójnych cudzysłowów daje preprocesorowi wskazówkę, gdzie powinien szukać plików nagłówkowych.
Kiedy używamy nawiasów kątowych, mówimy preprocesorowi, że jest to plik nagłówkowy, którego sami nie napisaliśmy. Preprocesor będzie wyszukiwał nagłówek tylko w katalogach określonych przez include directories. Słowo kluczowe include directories są skonfigurowane jako część projektu/ustawień IDE/ustawień kompilatora i zazwyczaj domyślnie będą to katalogi zawierające pliki nagłówkowe dostarczone z kompilatorem i/lub systemem operacyjnym. Preprocesor nie będzie wyszukiwał pliku nagłówkowego w katalogu kodu źródłowego projektu.
Kiedy używamy podwójnych cudzysłowów, mówimy preprocesorowi, że jest to plik nagłówkowy, który napisaliśmy sami. Preprocesor najpierw wyszuka plik nagłówkowy w bieżącym katalogu. Jeśli nie znajdzie tam pasującego nagłówka, przeszuka include directories.
Reguła
Użyj podwójnych cudzysłowów, aby uwzględnić pliki nagłówkowe, które napisałeś lub które mają znajdować się w bieżącym katalogu. Użyj nawiasów kątowych, aby uwzględnić nagłówki dostarczone z kompilatorem, systemem operacyjnym lub bibliotekami innych firm, które zainstalowałeś w innym miejscu w systemie.
Dlaczego iostream nie ma rozszerzenia .h?
Innym często zadawanym pytaniem jest: „Dlaczego iostream (ani żaden inny standardowy plik nagłówkowy biblioteki) nie ma rozszerzenia .h?”. Odpowiedź jest taka, że iostream.h jest innym plikiem nagłówkowym niż iostream! Wyjaśnienie wymaga krótkiej lekcji historii.
Kiedy tworzono C++, wszystkie nagłówki w bibliotece standardowej kończyły się sufiksem .h . Nagłówki te obejmowały:
| Typ nagłówka | Konwencja nazewnictwa | Przykład | Identyfikatory umieszczone w przestrzeni nazw |
|---|---|---|---|
| Specyficzne dla C++ | <xxx.h> | iostream.h | Globalna przestrzeń nazw |
| C kompatybilność | <xxx.h> | stddef.h | Globalna przestrzeń nazw |
Oryginalne wersje cout i cin zostały zadeklarowane w iostream.h w globalnej przestrzeni nazw. Życie było spójne i dobre.
Kiedy komitet ANSI ujednolicił język, postanowiono przenieść wszystkie nazwy używane w bibliotece standardowej do przestrzeni nazw std , aby uniknąć konfliktów nazewnictwa z identyfikatorami zadeklarowanymi przez użytkownika. Jednakże stwarzało to problem: jeśli przeniesiono wszystkie nazwy do przestrzeni nazw std , żaden ze starych programów (w tym iostream.h) nie będzie już działał!
Aby obejść ten problem, w C++ wprowadzono nowe pliki nagłówkowe, które nie mają rozszerzenia .h . Te nowe pliki nagłówkowe deklarują wszystkie nazwy w przestrzeni nazw std . W ten sposób starsze programy zawierające #include <iostream.h> nie muszą być przepisywane, a nowsze programy mogą #include <iostream>.
Nowoczesny C++ zawiera teraz 4 zestawy plików nagłówkowych:
| Typ nagłówka | Konwencja nazewnictwa | Przykład | Identyfikatory umieszczone w przestrzeni nazw |
|---|---|---|---|
| Specyficzne dla C++ (nowość) | <xxx> | iostream | std przestrzeń nazw |
| Zgodność z C (nowość) | <cxxx> | cstddef | std przestrzeń nazw (wymagana)globalna przestrzeń nazw (opcjonalna) |
| specyficzna dla C++ (stara) | <xxx.h> | iostream.h | Globalna przestrzeń nazw |
| Zgodność z C (stara) | <xxx.h> | stddef.h | Globalna przestrzeń nazw (wymagane)std przestrzeń nazw (opcjonalnie) |
Ostrzeżenie
Nowe nagłówki zgodności C <cxxx> mogą opcjonalnie deklarować nazwy w globalnej przestrzeni nazw, a stare nagłówki kompatybilności C <xxx.h> mogą opcjonalnie deklarować nazwy w std przestrzeni nazw. Należy unikać nazw w tych lokalizacjach, ponieważ nazwy te mogą nie być zadeklarowane w tych lokalizacjach w innych implementacjach.
Najlepsza praktyka
Użyj standardowych plików nagłówkowych bibliotek bez rozszerzenia .h. Nagłówki zdefiniowane przez użytkownika powinny nadal używać rozszerzenia .h.
Dołączanie plików nagłówkowych z innych katalogów
Inne częste pytanie dotyczy sposobu dołączania plików nagłówkowych z innych katalogów.
Jednym (złym) sposobem na zrobienie tego jest dołączenie ścieżki względnej do pliku nagłówkowego, który chcesz dołączyć jako część linii #include. Na przykład:
#include "headers/myHeader.h"
#include "../moreHeaders/myOtherHeader.h"Chociaż to się skompiluje (zakładając, że pliki istnieją w tych względnych katalogach), wadą tego podejścia jest to, że wymaga odzwierciedlenia struktury katalogów w kodzie. Jeśli kiedykolwiek zaktualizujesz strukturę katalogów, Twój kod przestanie działać.
Lepszą metodą jest poinformowanie kompilatora lub IDE, że masz kilka plików nagłówkowych w innej lokalizacji, aby mógł tam zajrzeć, gdy nie będzie mógł ich znaleźć w bieżącym katalogu. Zwykle można to zrobić poprzez ustawienie uwzględnienia ścieżki lub katalogu wyszukiwania w ustawieniach projektu IDE.
W przypadku użytkowników programu Visual Studio
Kliknij prawym przyciskiem myszy swój projekt w Eksplorator rozwiązań i wybierz Właściwości, a następnie zakładkę Katalogi VC++ . Stąd zobaczysz wiersz o nazwie Dołącz katalogi. Dodaj katalogi, w których kompilator ma przeszukiwać dodatkowe nagłówki.
W przypadku użytkowników Code::Blocks
W Code::Blocks przejdź do menu Projekt i wybierz Opcje kompilacji, a następnie zakładkę Wyszukaj katalogi . Dodaj katalogi, w których kompilator ma przeszukiwać dodatkowe nagłówki.
Dla użytkowników gcc
Używając g++, możesz użyć opcji -I, aby określić alternatywny katalog dołączany:g++ -o main -I./source/includes main.cpp
Po -I nie ma spacji. Aby uzyskać pełną ścieżkę (a nie ścieżkę względną), usuń . po -I.
Dla użytkowników VS Code
W Twoim tasks.json plik konfiguracyjny, dodaj nową linię w sekcji „args” :"-I./source/includes",
Po -I nie ma spacji. Aby uzyskać pełną ścieżkę (a nie ścieżkę względną), usuń . po -I.
Fajną rzeczą w tym podejściu jest to, że jeśli kiedykolwiek zmienisz strukturę katalogów, wystarczy zmienić tylko jeden kompilator lub ustawienie IDE zamiast każdego pliku kodu.
Nagłówki mogą zawierać inne nagłówki
Często zdarza się, że zawartość pliku nagłówkowego będzie wykorzystywać coś, co jest zadeklarowane (lub zdefiniowane) w innym pliku nagłówkowym. Kiedy tak się stanie, plik nagłówkowy powinien #zawierać drugi plik nagłówkowy zawierający deklarację (lub definicję), której potrzebuje.
Foo.h:
#include <string_view> // wymagane do użycia std::string_view
std::string_view getApplicationName(); // std::string_view użyta tutajGdy Twój plik źródłowy (.cpp) #zawiera plik nagłówkowy, otrzymasz także wszelkie inne pliki nagłówkowe #dołączone do tego nagłówka (oraz wszystkie pliki nagłówkowe, które zawierają itd.). Te dodatkowe pliki nagłówkowe są czasami nazywane dołączeniami przechodnimi, ponieważ są dołączone niejawnie, a nie jawnie.
Zawartość tych dołączeń przechodnich jest dostępna do wykorzystania w pliku kodu. Jednak generalnie nie należy polegać na zawartości nagłówków, które są dołączane przechodnio (chyba że dokumentacja referencyjna wskazuje, że te przechodnie są wymagane). Implementacja plików nagłówkowych może zmieniać się w czasie lub różnić się w różnych systemach. Jeśli tak się stanie, Twój kod może się skompilować tylko w niektórych systemach lub może się skompilować teraz, ale nie w przyszłości. Można tego łatwo uniknąć, jawnie dołączając wszystkie pliki nagłówkowe wymagane przez zawartość pliku z kodem.
Najlepsza praktyka
Każdy plik powinien jawnie #zawierać wszystkie pliki nagłówkowe, które musi skompilować. Nie polegaj na nagłówkach dołączonych przechodnio z innych nagłówków.
Niestety nie ma łatwego sposobu na wykrycie, kiedy plik kodu przypadkowo opiera się na zawartości pliku nagłówkowego, który został dołączony do innego pliku nagłówkowego.
P: Nie uwzględniłem <someheader>, a mój program i tak zadziałał! Dlaczego?
To jedno z najczęściej zadawanych pytań na tej stronie. Odpowiedź brzmi: prawdopodobnie działa, ponieważ umieściłeś inny nagłówek (np. <iostream>), który sam zawierał <someheader>. Chociaż Twój program się skompiluje, zgodnie z powyższymi najlepszymi praktykami, nie powinieneś na tym polegać. To, co kompiluje się dla Ciebie, może nie zostać skompilowane na komputerze znajomego.
Kolejność dołączania plików nagłówkowych
Jeśli Twoje pliki nagłówkowe są zapisane poprawnie i #include wszystko, czego potrzebują, kolejność włączania nie powinna mieć znaczenia.
Rozważmy teraz następujący scenariusz: powiedzmy, że nagłówek A potrzebuje deklaracji z nagłówka B, ale zapomina o tym. Jeśli w naszym pliku kodu umieścimy nagłówek B przed nagłówkiem A, nasz kod nadal będzie się kompilował! Dzieje się tak, ponieważ kompilator skompiluje wszystkie deklaracje z B, zanim skompiluje kod z A, który zależy od tych deklaracji.
Jeśli jednak najpierw dołączymy nagłówek A, kompilator będzie narzekał, ponieważ kod z A zostanie skompilowany, zanim kompilator zobaczy deklaracje z B. Jest to w rzeczywistości lepsze, ponieważ błąd został wykryty i możemy go następnie naprawić.
Najlepsza praktyka
Aby zmaksymalizować prawdopodobieństwo, że brakujące dołączenia zostaną oznaczone przez kompilator, zamów #includes w następujący sposób (pomijając te, które nie są istotne):
- Sparowany plik nagłówkowy dla tego pliku kodu (np.
add.cpppowinieneś#include "add.h") - Inne nagłówki z tego samego projektu (np.
#include "mymath.h") - nagłówki bibliotek innych firm (np.
#include <boost/tuple/tuple.hpp>) - Nagłówki bibliotek standardowych (np.
#include <iostream>)
Nagłówki dla każdego grupowania powinno być posortowane alfabetycznie (chyba że dokumentacja biblioteki innej firmy nie nakazuje inaczej).
W ten sposób, jeśli w jednym z nagłówków zdefiniowanych przez użytkownika brakuje #include dla biblioteki innej firmy lub nagłówka biblioteki standardowej, jest bardziej prawdopodobne, że spowoduje to błąd kompilacji, więc można go naprawić.
Sprawdzone praktyki dotyczące pliku nagłówkowego
Oto kilka dodatkowych zaleceń dotyczących tworzenia i używania nagłówka
- Zawsze dołączaj osłony nagłówka (omówimy to w następnej lekcji).
- Nie definiuj zmiennych i funkcji w plikach nagłówkowych (na razie).
- Nadaj plikowi nagłówkowemu taką samą nazwę, jak plik źródłowy, z którym jest powiązany (np.
grades.hjest sparowany zgrades.cpp). - Każdy plik nagłówkowy powinien mieć określone zadanie i być tak niezależny, jak to tylko możliwe. Na przykład możesz umieścić wszystkie deklaracje związane z funkcjonalnością A w A.h, a wszystkie deklaracje związane z funkcjonalnością B w B.h. W ten sposób, jeśli później zajmiesz się tylko A, możesz po prostu dołączyć A.h i nie uzyskać żadnych rzeczy związanych z B.
- Pamiętaj, które nagłówki musisz jawnie dołączyć dla funkcjonalności, której używasz w plikach kodu, aby uniknąć niezamierzonego przechodniości. zawiera.
- Plik nagłówkowy powinien #zawierać inne nagłówki zawierające potrzebną mu funkcjonalność. Taki nagłówek powinien #zawierać się samodzielnie w pliku .cpp.
- Dołącz tylko to, czego potrzebujesz (nie dołączaj wszystkiego tylko dlatego, że możesz).
- Nie #dołączaj plików .cpp.
- Wolę umieszczać dokumentację dotyczącą tego, co coś robi i jak to zrobić. użyj go w nagłówku Tam jest bardziej prawdopodobne, że dokumentacja opisująca działanie czegoś powinna pozostać w plikach źródłowych.